ADN-BIOINFORMÁTICA
Objetivo
El objetivo de esta práctica es estudiar la herramienta BLAST bioinformatics. Lo primero que haremos es leer las autorradiografías de secuenciaciones automáticas de geles. A continuación se analizan los datos resultantes utilizando las bases de datos públicas de BLAST para identificar los genes y productos genéticos.
Materiales
- Un juego de 4 tiras de autorradiografías


- Un ordenador con acceso a internet
- Caja de luz blanca

Procedimiento
-Ejercicio 1
Utilizaremos la tira de la secuencia 1
1. Comenzar en la flecha y leer hacia arriba el gel durante 20 nucleótidos. Escribir la
secuencia de ADN. Buscar la secuencia en la base de datos del NCBI utilizando el
programa BLASTN.
La secuencia es: ACAAATAGTTACCTTGGAAC



2. Comenzar en la flecha y leer hacia arriba el gel durante 30 nucleótidos. Escribir la
secuencia de ADN. Buscar la secuencia en la base de datos del NCBI utilizando el
programa BLASTN.
La secuencia es: ACAAATAGTTACCTTGGAACATCAAACGGA



Preguntas y resultados:
a. ¿Los resultados obtenidos con BLASTN para la primera y la segunda
búsqueda se parecen entre sí?
Los valores de las dos secuencias se parecen mucho entre sí, son casi idénticas
b. ¿Cuál es el nombre de este gen?
Factor de replicación C
Los valores de las dos secuencias se parecen mucho entre sí, son casi idénticas
b. ¿Cuál es el nombre de este gen?
Factor de replicación C
c. ¿A qué organismo es probable que pertenezca la secuencia de ADN de este
ejercicio?
Mus musculus ( ratón doméstico)
-Ejercicio 2
Utilizaremos la tira de la secuencia 2
1.Comience el ejercicio mediante la lectura de la secuencia de ADN de la muestra #2,
aproximadamente 6 cm desde la parte inferior de la tira. Los primeros 12 nucleótidos
deben ser: 5'...GGACGACGGTAT...3'.
2. Buscar la secuencia en la base de datos del NCBI utilizando el programa BLASTN.
3. Después de obtener los resultados del programa BLASTN, desplácese hacia abajo a
la sección de Alineamiento y mirar las entradas que tienen nucleótidos que coinciden
con su secuencia de consulta.


Preguntas y resultados:
a. ¿Cuál es el nombre de este gen?
UEV y dominios del lactato/malato deshidrogenasa
UEV y dominios del lactato/malato deshidrogenasa
b. ¿Cuál es la cadena simple que representa la secuencia de consulta? ¿Cuál es
la cadena simple que representa la secuencia “hit”?
La secuencia de consulta representa la cadena simple positiva (la introducida). La secuencia hit representa la cadena negativa (la inversa a la complementaria)
Ejercicio 3
Utilizaremos la tira de la secuencia 3
1. Lea la secuencia de ADN de la muestra #3. Comenzar desde la parte inferior de la
banda y escribir la secuencia de ADN.
2. Buscar la secuencia en la base de datos del NCBI utilizando el programa BLASTN.
3. Haga clic en el número de acceso de GenBank de la secuencia hit para acceder a
más información sobre la secuencia de ADN y/ gen.
La secuencia es: GATTTGTAATGTAAGTGAATAAGGAATACCATCTAGTTCAAAGAGAAAATGTAATTTTGAATGTGAATTATCTGTATGAAACATGAAGTATACCTACTGAACCCTGAAACATGCATGTCTAGATTTGCTTTTGTCCAATCCAGCCTGTTTGCAATCACTTCCTACTCAATATCCANGNNCGTNATNCTNTAGCTNAGGTGCATGGTGCGCACTNGNNNTGTCNCTNCGGTNGTNNNGCAGCAATGTTGCGTTCCATTCAGTAAAACGTACTGTGGAGTTCNGTGGACTNNNNNNNNNNNN



Preguntas y resultados:
a. ¿Cuál es el nombre de este gen?
Rho GTPasa activadora de la proteína 5
Rho GTPasa activadora de la proteína 5
b. ¿Cuántas pares de bases, aproximadamente, tiene este gen?
7933 pb
7933 pb
Ejercicio 4
Utilizaremos la tira de la secuencia 4
En esta sección se muestra la interacción de dos proteínas codificadas por dos genes.
Las interacciones proteína-proteína desempeñan un papel fundamental en
prácticamente todos los procesos en una célula viva
1. Lea la secuencia de ADN obtenido de la muestra #4. Comenzar desde la parte
inferior de la banda y escribir alrededor de 30 pares de bases de la secuencia de ADN.
2. A continuación, suba alrededor de un tercio de la altura de la tira (~ 14 cm) y leer
una parte de esta sección de la secuencia de ADN.
3. Para este ejercicio limitar la búsqueda a la base de datos de genes humanos. Para
ello vaya a "Choose Search Set” (Elija conjunto de búsqueda) y seleccione "Human
genomic + transcript” (Genóma humano + transcripción). Ver Guía para el uso de
BLASTN, punto 7.
4. Buscar cada sección de la secuencia de forma individual en la base de datos del
NCBI utilizando el programa BLASTN.
5. Una vez haya identificado el nombre de estos dos genes, realice una búsqueda
general de Internet para recoger más información acerca de las dos proteínas.
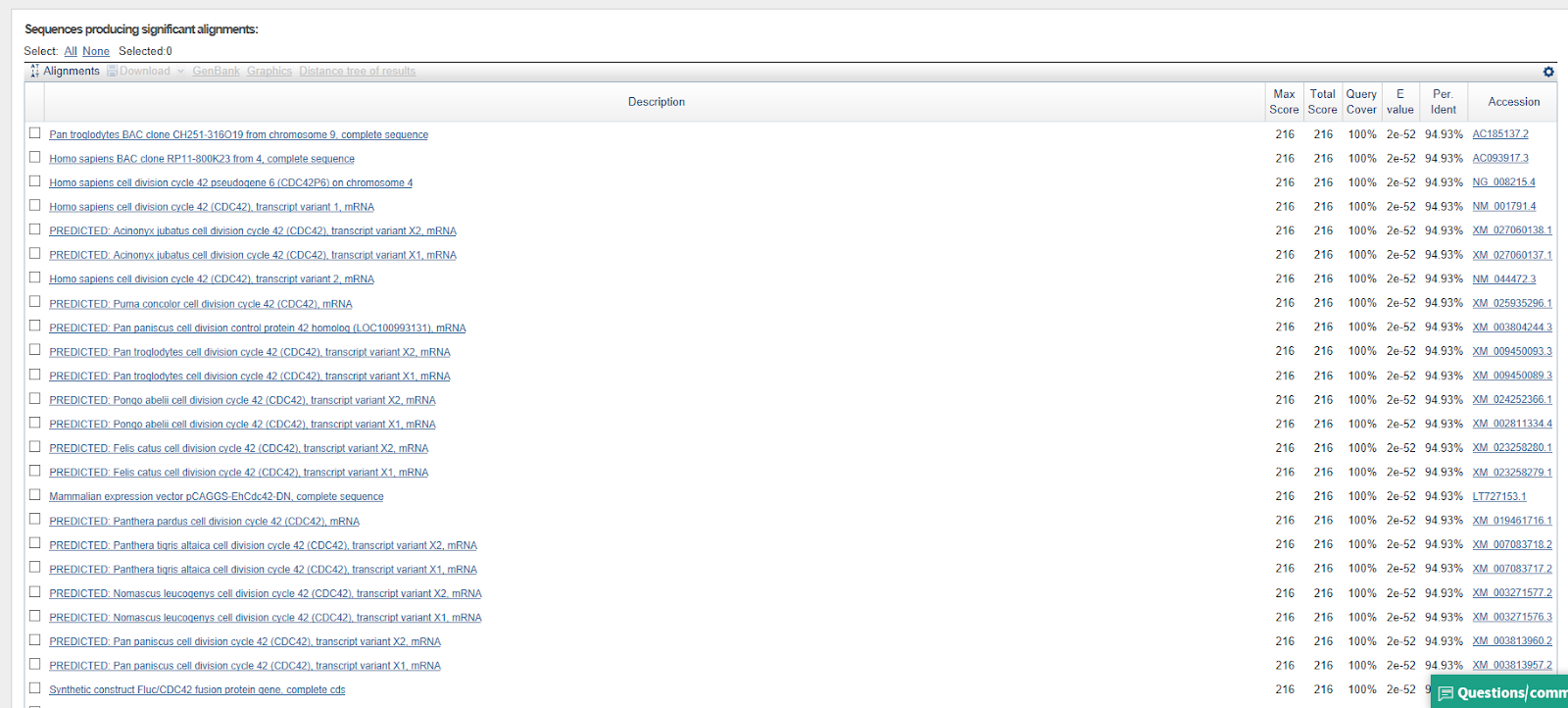
La secuencia es: ACAGCTTGGGTGGTCATATGGCCATGGAGC



La misma secuencia, pero 14 cm más arriba



La misma secuencia, pero 14 cm más arriba
Preguntas y resultados:
a. Este ejercicio contiene dos secuencias de ADN (desde la sección inferior y a
partir de la sección central). ¿Cuáles son los nombres de los genes
correspondientes a estas dos secuencias?
La primera secuencia de ADN es la de Bai 1. La segunda secuencia es la de Rac 1
La primera secuencia de ADN es la de Bai 1. La segunda secuencia es la de Rac 1
b. ¿Cuáles son las funciones de las dos proteínas codificadas por estos genes?
La secuencia Bai1 codifica BAI1, un inhibidor de la angiogénesis específica del cerebro. La angiogénesis implica el crecimiento de nuevos vasos sanguíneos a partir de vasos pre-existentes, es un proceso normal en el crecimiento, desarrollo y cicatrización de heridas. Sin embargo, la angiogénesis también ha demostrado ser esencial para el crecimiento y la metástasis de tumores sólidos. Con el fin de obtener el suministro de sangre para su crecimiento, las células tumorales son potentemente angiogénicas. La BAI1 se cree que inhibe el nuevo crecimiento de las células de los vasos sanguíneos, por lo que suprime el crecimiento de los glioblastomas (tumores cerebrales malignos). La BAI1 también se cree que funciona en la adhesión celular y transducción de señales en el cerebro. La secuencia Rac1 codifica una pequeña GTPasa llamada RAC1. La RAC1 actúa como un interruptor molecular en las vías de señalización que pueden cambiar la transducción de señales hacia dentro y fuera de una célula. La RAC1 está activo u "ON" cuando se une a una GTP e inactiva u "OFF" cuando se une con a un PIB. La forma inactiva de RAC1 (PIB-forma) se activa mediante el intercambio de GDP por GTP por los factores de cambio de nucleótidos de guanosina (GEFs). La inactivación de la RAC1 se consigue mediante la activación de las proteínas GTPasa (GAP), que revierten la conformación de nuevo a la forma inactiva unida a GDP a través de la hidrólisis del GTP.
La secuencia Bai1 codifica BAI1, un inhibidor de la angiogénesis específica del cerebro. La angiogénesis implica el crecimiento de nuevos vasos sanguíneos a partir de vasos pre-existentes, es un proceso normal en el crecimiento, desarrollo y cicatrización de heridas. Sin embargo, la angiogénesis también ha demostrado ser esencial para el crecimiento y la metástasis de tumores sólidos. Con el fin de obtener el suministro de sangre para su crecimiento, las células tumorales son potentemente angiogénicas. La BAI1 se cree que inhibe el nuevo crecimiento de las células de los vasos sanguíneos, por lo que suprime el crecimiento de los glioblastomas (tumores cerebrales malignos). La BAI1 también se cree que funciona en la adhesión celular y transducción de señales en el cerebro. La secuencia Rac1 codifica una pequeña GTPasa llamada RAC1. La RAC1 actúa como un interruptor molecular en las vías de señalización que pueden cambiar la transducción de señales hacia dentro y fuera de una célula. La RAC1 está activo u "ON" cuando se une a una GTP e inactiva u "OFF" cuando se une con a un PIB. La forma inactiva de RAC1 (PIB-forma) se activa mediante el intercambio de GDP por GTP por los factores de cambio de nucleótidos de guanosina (GEFs). La inactivación de la RAC1 se consigue mediante la activación de las proteínas GTPasa (GAP), que revierten la conformación de nuevo a la forma inactiva unida a GDP a través de la hidrólisis del GTP.
c. ¿Cómo interactúan estas dos proteínas en una célula viva?
En una célula viva, después de la Rac 1
En una célula viva, después de la Rac 1